
Predicting Oscar Winners Using Machine Learning Techniques

Predicting the Oscar winners has always been the favorite game of journalists and gamblers of all kinds, as the annual Academy Awards approaches. However, it can be very complex for several reasons. Through this project, I wanted to try my hand at this game by applying well-known data science techniques.
I will describe how I created a classifier than can predict oscar winners using Logistic Regression. More importantly, I will show you how I incremently improved my model, as I had to do some trade-offs, giving up some ideas and exploring new paths.
I) The dataset
Before thinking of models, algorithms and features, a data science project always starts by the data set.
First of all, I needed a list of all the oscar nominees since 1928 (First Academy Awards Ceremony). You can easilly find this list on google. I got mine here and scraped this website using BeautifulSoup. If you are not familiar with BeautifulSoup, go check my tutorial.
This award nominees/winners list focuses on the 4 main award categories (best picture, best director, best actor(actress), best supporting actor(actress)), which was fine as I just wanted to predict if a movie won any oscar and because the initial dataset still had a fairly substential size (~= 1120 movies). The list of movies looks like this at this time:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Now we need to get more data on these movies. I simply used the OMDB api, since IMDB doesn’t provide a proper api and you still need to scrape its website to get the data you need. OMDB founder already scraped IMDB website and give access to it through its api.
For each movie, I queried the api using movie title and year.
To get financial data the api didn’t have, such as budget or domestic total gross I scraped the IMDB website using the imdb-id the api was returning.
I ended up with a dataset of 1093 records and 42 fields for each movie.
II) Feature Selection
Before bulding my model, I needed to chose the fields that would become the features of my model. Intuitively one can imagine that features such as reviews, ratings, box office gross or the number of nominations in the other award ceremonies are likely to influence the results of the Oscars. On the contrary, runtime, imdbID or title contain very little information as to the success of the film at the Oscars.
I focused on logistic regression for this project, but you can clearly try other classification techniques such as SVM or Random Forest and see if it improves the precision of your model.
I have run several cross validation tests and feature selections (using SelectKBest function of scikit learn package) on different feature sets, and I found that the best variance-bias tradoff was reached for the following features:
IMDB Ratings: IMDB weighted average ratingWinPercentage: percentage of awards won among all nominations.
III) Tweaking the model
Whether a classifier is “good” really depends on:
What else is available for your particular problem. Obviously, you want a classifier to be better than random or naive guesses (e.g. classifying everything as belonging to the most common category) but some things are easier to classify than others.
The cost of different mistakes (false alarm vs. false negatives) and the base rate. It’s very important to distinguish the two and work out the consequences as it’s possible to have a classifier with a very high accuracy (correct classifications on some test sample) that is completely useless in practice (say you are trying to detect a rare disease or some uncommon mischievous behavior and plan to launch some action upon detection; Large-scale testing costs something and the remedial action/treatment also typically involve significant risks/costs so considering that most hits are going to be false positives, from a cost/benefit perspective it might be better to do nothing).
In the context of binary classification, examples are either positive or negative. The recall addresses the question: “Given a positive example, will the classifier detect it ?” The precision addresses the question: “Given a positive prediction from the classifier, how likely is it to be correct ?”
So it depends if the focus is on positive examples or on positive predictions.
In the oscar prediction model, precision is the most important validation metric, because if you want to bet money on future Oscar winners, your predictions would better to be correct!
In order to get the maximum precision I changed some of the model parameters such as the inverse of the regularization strength, C and the logistic regression threshold.
Here is the graph of the precision score as a function of C:
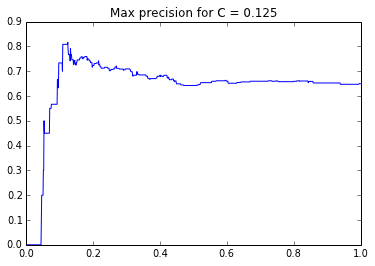
I had to extend the scikit-learn Logistic Regression class to modify the threshold:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Here is the graph of the precision score as a function of the threshold:
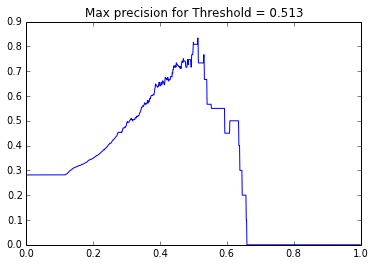
IV) Results & Tests
I finally tested my model with the Oscar nominees from 2011 to 2014. My model predicted that Dallas Buyers Club and Gravity were going to win an Oscar. As my focus was on the precision score, I only got 2 predictions, but these were right!